Natural Language Processing for Sustainable Development
What
Pulse Lab Jakarta had launched Translator Gator, a people-powered language game to support research initiatives in Indonesia by translating a pre-defined set of 2,000 English keywords and phrases related to the Sustainable Development Goals (SDGs) to six Indonesian languages (Bahasa Indonesia, Jawa, Sunda, Bugis, Minang, and Melayu). The game enabled the Lab to compile user-created dictionaries of words which help Global Pulse and partners in carrying out automated analyses of social media, to better understand which issues matter to people and what they are saying about education, health, climate change, and other key development issues.
Gaming proved to be a powerful and efficient way to tap into the 'wisdom of the crowd'. After gathered more than 109,000 user contributions from hundreds of players from across Indonesia, 19 computational linguistic experts and advisors from 18 different universities and government research institutions were invited to collaboratively explore and analyze the data. Broken up in groups, participants were tasked with assessing the quality of the translations, visualizing the data to make better sense of it, and filling in important translation gaps.
The participants were grouped into into four research teams, focusing on:
- Group 1 - Analysis of the corpus in Bahasa Indonesia
- Group 2 - Analysis of parallel corpora
- Group 3 - Analysis of informal expressions or the quality of translation
- Group 4 - Visualization of Indonesian corpora
The information package of the first Research Dive is accessible here: http://bit.ly/infopackage-RD1
Group 1: Expanding Corpus by Enlarging Translation using Morphosyntax
Abstract
This document describes our work on expanding corpus by enlarging translation using morpho-syntax. The corpus used in this work is from Translator Gator data. We use several methods to expand a list of synonymous words, such as by evaluating Levenshtein distance and structure of the text. The resulting synonym list is compared to Google Translate.
Result
Enlarging Corpus with expanding the translation result from English to Indonesian can use the similarity checking. Using checking the similarity by Levenshtein Distance and also check the structure in Indonesian Language can give more reliable result translation. The meaning from each word in Indonesian sentence will be different depend on the position in the sentence or tagger. For the further research the expand translation will be checking for more than two words or phrase.
Group 2: Enriching English into Sundanese and Javanese Translation List Using Pivot Language
Abstract
This paper discusses the problem of sparse translation of English into Sundanese and Javanese that were found in Translator Gator. Translator Gator is a language game created by Pulse Lab Jakarta, to support the research initiatives in Indonesia. Thousands of keyword were generated and translated from English into some Indonesian local languages using the crowd resource. Unfortunately, many English words are still has no translation in Javanese as well as Sundanese. To overcome this problem we propose a technique to fill the un-translated English words in Javanese and Sundanese using Indonesian translation as a pivot language. Evaluation was made by manually investigated whether each phrase results a proper translation. Experiment shows that our technique results relatively low translation accuracy. Limited coverage of phrase translation list and ambiguous words are identified as causes of translations errors in our technique.
Result
By using 1324 unique English keyword from 36.313 transactional data translation that translated by more than 100 Translator Gator users, the translation produced 269 Javanese phrase translation and 1149 Sundanese translations. It shows that our dictionary that was built using existing translator gator translation list covers less than 30% of the whole translation. In this experiment, we evaluate all translation results of Indonesian-Javanese (ID-JW). While for Indonesian-Sundanese (ID-SU) translation we used only some translation sample determined using Slovin formula of ID-SU since a large number translation thus its relatively hard to evaluate all of these translation manually. Below are table shows the translation result evaluation.
|
Rule Applied to translation |
Number of Evaluated Samples |
Percentage of keywords translated properly |
|
Indonesian – Javanese (ID-JW) |
||
|
Rule #1 (using phrase translation / dictionary) |
76 |
58 of 76 (76.3%) |
|
Rule #2 |
193 |
42 of 193 (22.6%) |
|
Total ID-JW evaluated sample |
269 |
|
|
Indonesian – Sundanese (ID-SU) |
||
|
Rule #1 (using phrase translation / dictionary) |
68 |
60 of 68 (88%) |
|
Rule #2 |
229 |
78 of 229 (34%) |
|
Total ID-SU evaluated sample |
297 |
|
Our experiment shows that the proposed technique by our team does not provide the accurate translation. We found that averagely our technique only reach 37% correct translation result of Indonesian-Javanese and 46% of Indonesian-Sundanese translation. However, this technique gives contribution to create a better translation pair from existing Translator Gator data, which gives more than 65% proper phrase translation for both Indonesian-Javanese and Indonesian-Sundanese pair translation. In the future, using dictionary to entail the translation quality is preferable.
Group 3: Discover Best Feature Combination of User Behavior in Indonesian Corpus Collection Based Incentive Crowdsourcing
Abstract
The research aims to classify translation correctness of translator gator dataset obtained from crowd-sourcing to evaluate features that affect translation. The nine features used for classification are Number of vote up and vote down, Frequency of word, Lifetime in seconds, Class (Correct or incorrect translation), Weighted vote up (number of vote up/lifetime), Weighted vote down (number of vote down/lifetime), and Diff score (weighted vote up-weighted vote down). Based on feature selection testing using Naïve Bayes, Random Forest, SVM, and J-48 method, it can be concluded the frequency feature can be combined with the weighted vote up and vote down for classifying the correct and incorrect translation. Diff score as differentiation of weighted vote-up and vote-down feature contributes poor result. However the combination of frequency and diff score using random forest method gives more accurate results with correctness percentage of 80.01% and can be used as alternate to classified the correct and incorrect translation.
Result
Based on the experimental results, vote up, vote down and lifetime affect the user translation in crowdsourcing incentive method with the percentage of correctly classified instance 80.53% and 71.32% by Naïve Bayes and Random Forest methods. Weighted vote up and weighted vote down as the ratio of vote up, vote down and lifetime respectively, give a better results with the percentage of correctly classified instance 81.10% and 79.95%. Moreover, the accuracy of combination of frequency, weighted vote up, and weighted vote down features slightly decrease from just weighted vote up and vote down features with the percentage of correctly classified instance 73.55% and 80.06%. However, the number of false positive and false negative are less than before. It can be conclude that frequency feature can be combined with weighted vote up and weighted vote down to classified the correct and incorrect translation.
Diff score as the differentiation of weighted vote up and weighted vote down feature give a slightly worst result. However, the combination of frequency and diff score give a better accuracy with the percentage of correctly classified instance 80.01% based on random forest method. So, frequency and diff score can be used as alternate to classified the correct and incorrect translation.
Group 4: MIDVIS: Pyramid Visualization of SDGs Understanding in Indonesian Community
Abstract
Translator Gator is a crowdsourcing translation with an incentive inspired by the need to socialise the 17 Sustainable Development Goals (SDGs) and 10 of Indonesian government’s programmes. The huge number of Translator Gator data makes it hard to see and understand the data especially for decision maker users or end users. Therefore, MIDVIS (Pyramid Visualization) is designed and created to solve that problem. We also offer two alternative visualizations: Recurvise Aristotle’s Square of Opposition visualization and Zoomable Wordmap visualization. MIDVIS visualizes the inverse rank, which is the most important information in the smallest part on the top of the pyramid. Recurvise Aristotle’s Square of Opposition visualizes the most understood word and the most confusing word. Users can see the less understood and less confusing words with a mouse click to zoom in the recursive square. Zoomable Wordmap is useful to compare the level of understanding of each area/language. For further works, a creative essay about SDGs and Indonesia’s programme can be constructed automatically by a computer using a computational linguistic method.
Result
The MIDVIS homepage displays a pyramid consisting of 17 SDGs sorted from the most confusing criteria to the least confusing criteria. Users can click an SDG criteria and the MIDVIS will display a map of Indonesia. The colors of Indonesia map area is gradated from the chosen color representation of SDG toward lighter color in 6 level gradation. People in regions with the darker color are the ones who understand SDG better while people in regions with the lighter color have the least understanding of SDG. Users can see some information, such as location name, two languages used by local people in that location, the total number of all terms that have been translated, and some example terms that have been translated while hovering at some area in the map.
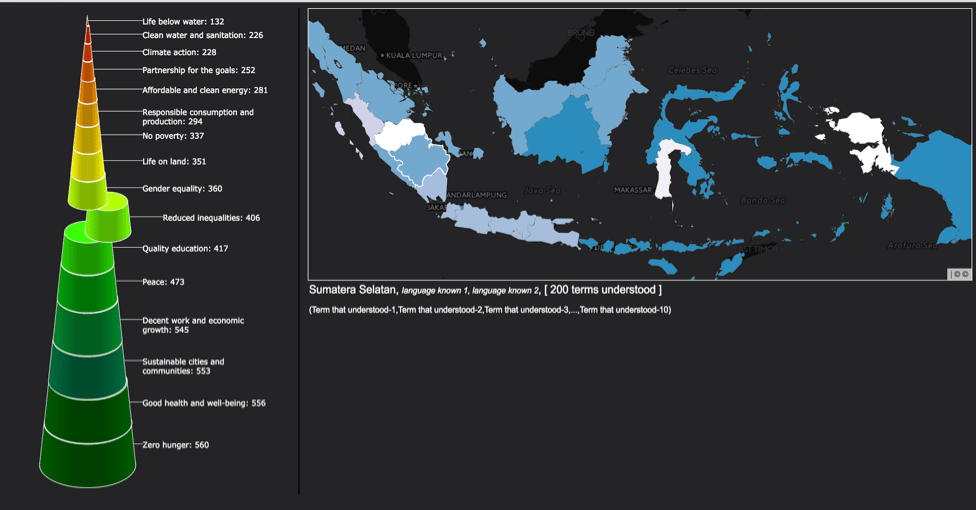
MIDVIS Visualization
Advisors
| Dr. Eng. Ayu Purwarianti, ST., MT | Institut Teknologi Bandung |
| Dr. Suhandano, M.A. | Universitas Gajah Mada |
Participants
Group 1 – Analysis of the corpus in Bahasa Indonesia
| Achmad F. Abka | Indonesian Insitute of Sciences |
| Badrus Zaman | Airlangga University |
| Firdaus Solihin | Trunojoyo University |
| I Putu Gede Hendra Suputra | Udayana University |
| Yulyani Arifin | Bina Nusantara University |
| Imaduddin Amin | Pulse Lab Jakarta |
Group 2 – Analysis of parallel corpora
| Arie Ardiyanti Suryani | Telkom University |
| Bagus Setya Rintyarna | Muhammadiyah Jember University |
| Banu Wirawan Yohanes | Satya Wacana Christian University |
| Isye Arieshanti | Sepuluh Nopember Institute of Technology |
| Sari Dewi Budiwati | Telkom University |
| Muhammad Subair | Pulse Lab Jakarta |
Group 3 – Analysis of informal expressions or the quality of translation
| A'la Syauqi | Islamice State University of Malang |
| Adi Heru Utomo | State Polytechnic of Jember |
| Fika Hastarita Rachman | Trunojoyo University |
| Lya Hulliyatus Suadaa | Institute of Statistics |
| Novita Hanafiah | Bina Nusantara University |
| Satyaning Paramita | Pulse Lab Jakarta |
Group 4 – Visualization of Indonesian corpora
| Hendra Bunyamin | Christian Maranatha University |
| Iwan Njoto Sandjaja | Petra Christian University |
| Ni Made Satvika Iswari | Multimedia Nusantara University |
| Retno Kusumaningrum | Diponegoro University |
| Muhammad Rheza | Pulse Lab Jakarta |